Embedded C_Lecture 2
Embedded C Overview
1. From high level language to hardware language
컴퓨터, 또는 MCU 및 제어기는 CPU라는 두뇌와 Memory라는 연습장을 가지고 연산을 하는 기계다. 연산의 단위는 CPU 내에 있는 register라는 임시 저장소의 크기가 되며, 만일 register가 32bit인 경우 Instruction Set Architecture(ISA)에 따라 operation 및 operand가 32개의 비트에 하나하나 새겨지게 된다. 기계는 이런 32개의 0과 1의 조합으로 명령을 수행하는 것이며, 인간이 기계어를 직접 짜는 것은 매우 번거로운 일이기 때문에 C언어와 같은 high level language를 작성하고 compiler, assembler, 그리고 linker와 같은 도구를 통해 기계어로 번역한다. 과정을 그림으로 나타내면 아래와 같다.
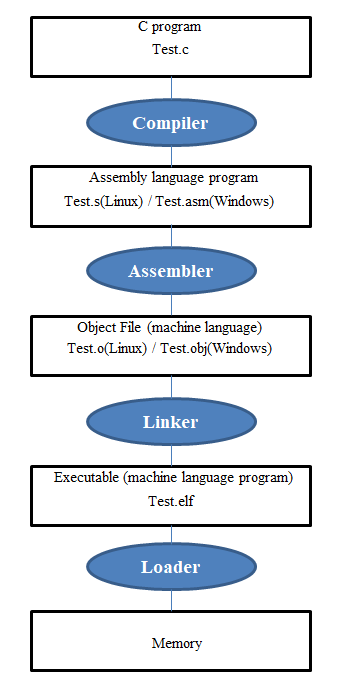
link editor에서 이름이 유래된 linker는 여러 .c 파일을 .o 파일로 변환하고 나서 dependency들을 고려하여 하나로 묶어주는 기능을 수행하며, #include에 의해 호출되는 여러 function들에게 주소를 부여하여 코드가 메모리 내에 mapping 되도록 한다. 만약 linker script를 이용해서 memory 상에 특정 주소 공간에 함수 및 전역변수의 주소를 설정하지 않는다면 linker에 의해 순차적으로 주소가 부여된다. linker에 의해 나오는 output은 .elf 파일로 extensible linkable format이라는 확장자이다.
요새는 보통 compiler와 assembler를 통합해서 compiler라고 부른다. 또한, C언어보다 더 high level language로 python과 같은 언어가 있으며 MATLAB 시뮬링크와 같이 모델 기반 프로그래밍 기법이 있기도 하다. MATLAB의 경우 모델 기반 스크립트를 coder라는 프로그램을 통해 C언어로 변환하는 기능을 제공한다.
2. Memory
CPU가 접근하는 메모리의 주소 공간은 아래와 같이 나눌 수 있다. SRAM과 같은 main memory 뿐만 아니라 NOR Flash와 같이 byte addressible한 소자라면 ROM 또한 주소 공간의 일부를 구성할 수 있다.
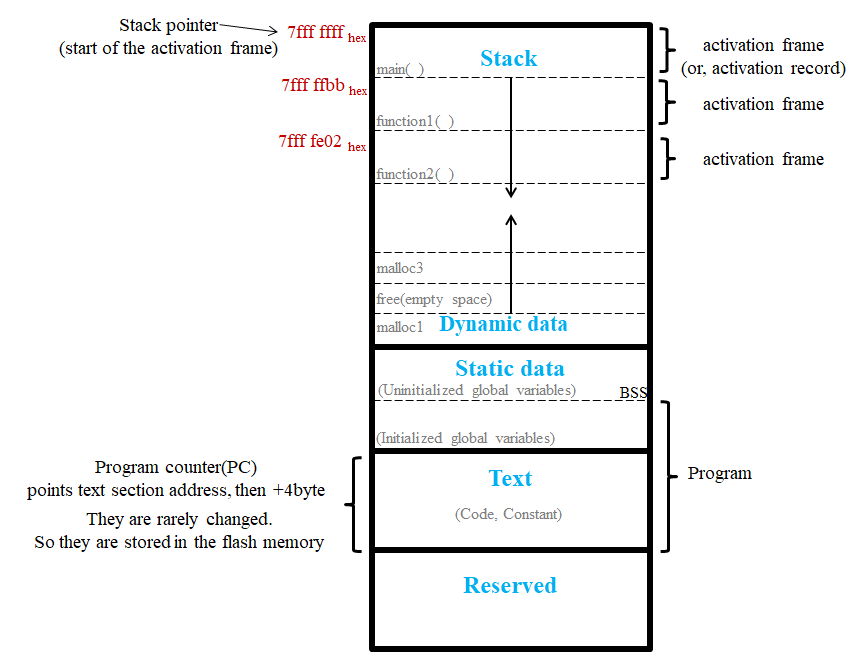 그림 1. memory layout
그림 1. memory layout
2-1. Text
Code segment라고도 하며, Text영역은 상수 및 내가 작성한 함수를 비롯한 코드의 내용이 저장되는 곳이다. 상수는 ‘a’, ‘b’ 와 같은 문자 및 1, 2, 3 과 같은 숫자들을 일컫는 말이지만 전역변수에 const를 붙이게 되면 static data가 아니라 text에 저장되게 된다. 즉, 프로그램 실행 이후 더이상 변할 일이 없는 데이터 들은 모두 text 영역의 주소에 mapping 되는 것이다. 또한 어셈블리로 번역된 instruction은 모두 text 영역에 주소로 할당되어 있으며 이 주소들을 CPU 안에 있는 Program counter(PC)가 이 주소값들을 가지고 있다. CPU는 PC가 가리키는 주소에 있는 instruction들을 차례로 실행하고, 4byte씩(register가 32bit 인 경우) 주소를 더하며 다음 instruction을 실행하는 식으로 프로그램이 동작하게 된다.
2-2. Static data
Static data 영역은 프로그램이 끝날 때 까지 고정된 주소를 할당받은 데이터들이 모여있는 공간으로, 보통 전역 변수들이 선언되는 경우 이 static 영역에 있는 주소로 mapping 된다. 다만 선언한 전역 변수의 초기화 유무에 따라 주소 공간이 한 번 더 나뉘며, BSS(Block Started by Symbol)라는 공간에는 코드 상 초기화 되지 않은 전역 변수들이 한 번에 0으로 초기화가 된다.
static 키워드를 사용해서 변수를 static으로 선언해줄 수도 있다. 아래의 경우를 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <stdio.h>
static int c = 10;
int function1()
{
int a = 10;
static int b = 10;
a++;
b++;
return 0;
}
int main()
{
for(int i = 10; i>0; i--)
{
function1();
}
return 0;
}
main 함수에서 function1()을 10번 호출하는 경우, 지역변수인 a는 함수가 return 되자마자 사라지는 값이지만, b는 static 영역에 남아있게 되어 20이 된다. (static 키워드가 붙는 경우 function1()이 10번 실행되는 경우 초기화는 프로그램 시작 시에만 된다.) 마치 전역변수 처럼 static 공간에서 남아 프로그램이 끝날 때 까지 값이 기억되지만, 변수 b는 함수 function1()을 통해서만 접근할 수 있도록 scope가 변경된다.
한편 static으로 선언된 전역 변수 c는 일반 전역 변수와 어떤 차이를 가질까? 마치 함수 내에서 선언된 static 변수는 함수를 통해서만 접근이 가능하도록 scope가 변경된 것처럼, .c파일 내에서 선언된 static 전역 변수는 해당 파일 내에서만 접근이 가능하게 된다. 이렇듯 static 키워드는 해당 변수의 scope를 줄이는 역할을 한다.
2-3. Dynamic data
heap 공간이라고도 한다. C에서는 malloc/free 키워드를 사용하여 동적 메모리를 할당 및 해제한다. 동적 할당은 보통 크기가 아직 정해지지 않은 변수를 선언할 때 사용한다. 예를 들어 크기가 가변적인 배열을 선언한다고 할 때, x라는 변수에 배열의 크기를 받도록해서 int myarr[x]; 로 배열을 선언하는 방식을 생각해 볼 수 있다. 하지만 이는 컴파일 시 오류가 나는데, 컴파일 시 크기가 정적으로 결정되는 스택 영역에는 가변적인 크기를 가지는 데이터를 선언할 수 없기 때문이다. 이 때는 malloc을 사용하여 heap 공간에 변수를 선언해주도록 하자.
하지만 주의할 점이 있다. stack에 있는 변수들은 자동적으로 컴파일러에 의해서 관리가 되지만, heap에 있는 변수들은 사용자가 직접 관리를 해야한다는 것이다. 예를 들어 내가 위의 그림 1과 같이 malloc으로 세 개의 변수를 선언하고(편의를 위해 각각 malloc1, malloc2, malloc3이라고 하자.) malloc2는 free시켜준 경우, malloc1과 malloc3 사이에 빈 주소 공간이 남게된다. 이를 fragmentation이라고 하는데, 이런 빈 주소공간을 정리하지 않고 계속 malloc을 사용하다 보면 구멍이 뚫린 상태로 heap 영역이 stack을 침범하여 stack overflow가 발생할 수 있다. C는 이를 직접 개발자가 관리해야하지만, 파이썬이나 Java는 빈 공간이 남지 않도록 garbage collector가 관리를 자동으로 해준다.
2-4. Stack
매개변수나 지역변수 들의 메모리가 할당되는 곳이다.
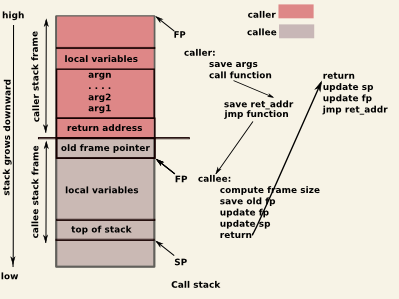
위 그림은 함수가 호출될 때 stack에 메모리가 할당되는 과정을 나타낸 것이다. caller 함수에서 callee 함수를 호출하는 경우 caller 함수가 차지하는 stack frame에 매개변수와 호출한 함수가 종료됬을 때 복귀할 명령어의 주소(return address)가 추가된다. 그 후 callee 함수의 지역변수가 차지하는 공간이 stack frame에 잡히게 되며, callee가 return을 만나면 해당 stack frame은 stack에서 해제가 되어 return address를 읽고 원래 함수가 계속해서 실행할 곳으로 돌아갈 수 있게 된다.
참고로 컴파일러는 최적화를 위해 지역변수의 경우 최대한 레지스터에 바로 등록하여 쓰도록 빌드한다. 따라서 지역변수를 많이 쓰는 코드일수록 레지스터의 사용빈도가 늘어나서 속도가 향상되는 효과를 기대할 수 있다.
3. Integer
3-1. Size
앞선 설명에서 말했듯이, 레지스터가 한 번에 처리할 수 있는 데이터의 사이즈를 1 word라고 했다. 만약 내가 사용하는 CPU의 레지스터가 32bit라면, 1 word는 32bit인 셈이다. 한편 데이터 연산의 효율성, 하드웨어 설계적 측면 등 다양한 이유로 정수형은 기본 자료형 으로 사용되며, 그 크기는 레지스터가 연산하기 편하도록 레지스터의 크기에 맞추도록 하드웨어 아키텍처가 설계된다. 예를 들어서, 32bit MCU에서 int 자료형은 32bit 이다.
Register의 크기에 따라 MCU 별 자료형이 가지는 크기는 아래의 표와 같다.
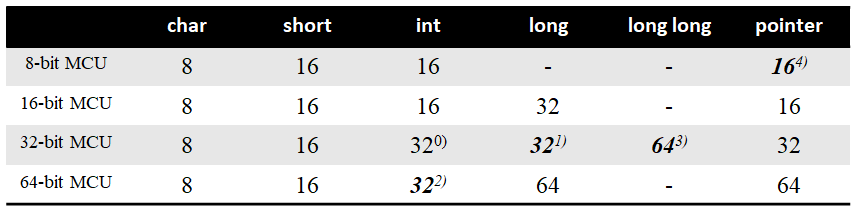
먼저 16-bit MCU는 자료형의 크기가 모두 합리적이다. int를 16-bit로 맞춰놓고, 문자를 표현하는 char의 경우 8-bit면 충분하고, short의 경우 16과 8 사이 값이 애매하기 때문에 16을 할당, long의 경우 32bit를 할당, 그리고 pointer의 경우 16bit로 표현할 수 있는 모든 수를 access 하기 위해 16bit의 크기를 가져야 한다.
그 다음엔 0)으로 주석처리가 되어 있는 32-bit MCU의 int형에서 시작하면 이해하기 편하다. int는 register의 크기와 같아야 하기 때문에 32bit의 크기를 가지며, 1)과 같이 long이 32bit인 이유는 32-bit MCU가 만들어졌을 당시 16-bit MCU를 기반으로 작성한 코드가 호환성을 최대한 유지하기 위해서이다. long long은 잠시 놔두고 64-bit MCU로 가보자.
64-bit MCU가 만들어지고 나서는 int형이 64bit가 되어야 할 것 같지만, 그렇게 되는 경우 8bit로 유지되는 char와 int 사이에 있는 short의 크기가 애매해지기 때문에, 2)와 같이 32bit로 정하기로 했다. 그리고 long을 64bit크기로 정의했는데, 널리 쓰이고 있던 32-bit MCU를 기반으로 작성한 코드가 64-bit MCU와의 호환성을 위해 3)과 같이 long long이라는 64bit 크기의 자료형이 32 bit MCU에 추가되었다.
pointer 자료형의 크기는 MCU가 한번에 표현할 수 있는 수에 대해서 1대 1로 주소 체계를 가지고 있어야 하기 때문에 register의 크기와 같다. 그러나 4)와 같이 예외적으로 8-bit MCU의 경우 포인터 자료형을 16bit가 되도록 설계했는데, 이는 8-bit로 포인터 자료형을 정의할 경우 access 할 수 있는 데이터가 지나치게 작아지기 때문이다.
이런식으로 같은 데이터 타입이어도 자료형의 크기가 MCU별로 상이하기 때문에 MISRA에서는 stdint.h를 #include 시켜 uint8_t, int32_t와 같이 크기가 명시된 형태의 자료형을 쓸 것을 권장하고 있다.
3-2. Negative number
양수와 음수는 데이터의 MSB(Most significant bit, 데이터의 최상위 비트)가 0과 1 중 어떤 값을 가지는지에 따라 달라진다. MSB가 0으로 시작하면 양수이고, 1로 시작하면 음수가 된다. 어떤 양의 정수를 음수로 바꾸는 방식은 양의 정수에 보수를 취하고 1을 더하는 방식으로 한다. MSB가 1이면 음수라면서, 왜 이런 복잡한 방식을 취한 것일까? 여기엔 나름의 이유가 있다.
먼저 MSB에 0과 1만 사용하는 방식으로 부호를 결정하면 아래와 같이 10진수가 2진수로 표현된다.
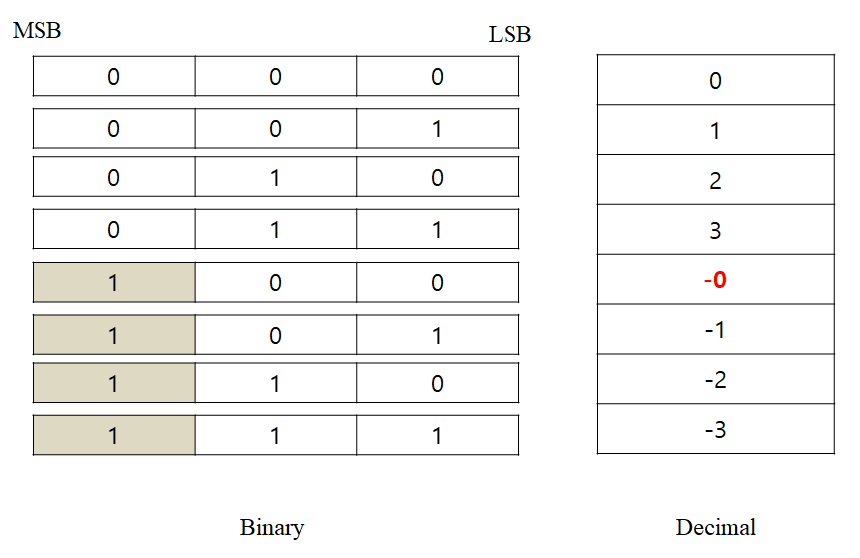
그러나 위의 경우 -0이 생기면서 0이라는 수를 두 가지 방식으로 표현하게 되는 문제가 생기게 된다. 그렇다면 양수에다가 보수를 취하는 방식은 어떨까? 아래 그림과 같은 결과가 나타나게 된다.
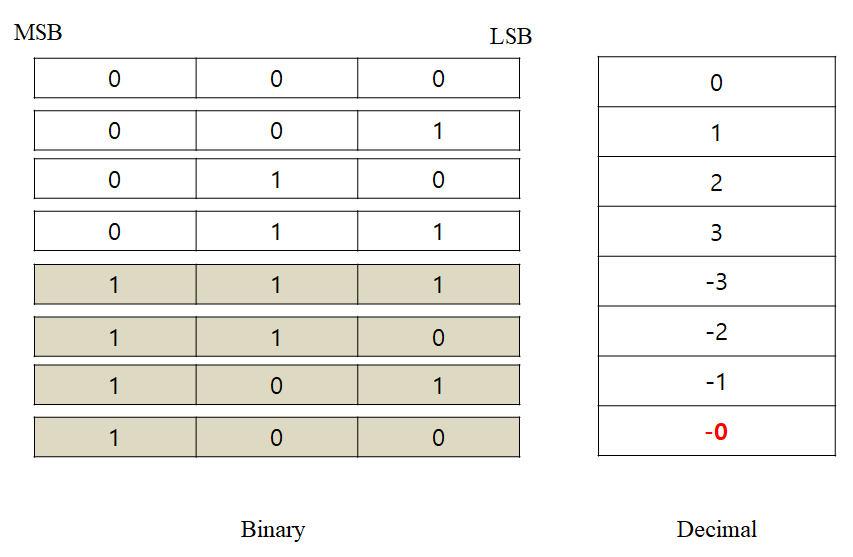
보수를 취하는 방식이어도 여전히 -0가 존재하게 된다. 하지만 보수를 취한 결과에 1만 더해주면 모두가 행복해지는 결과를 얻게 된다. 아래와 같이 말이다.
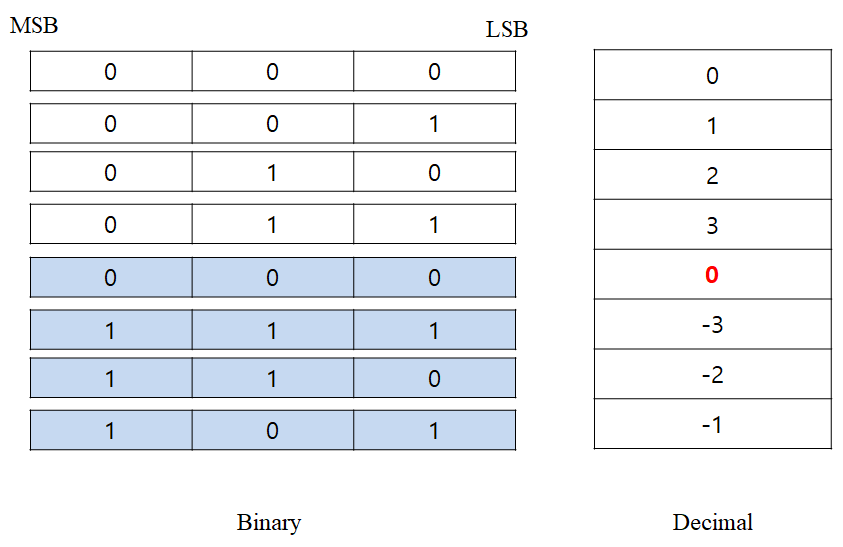
C언어에서 선언되는 모든 정수 자료형은 위와 같은 규칙에 따라 메모리에 binary 형태로 표현되게 된다.
4. Decimal point
실수가 메모리에 binary 형태로 저장되는 방식은 부동 소수점 방식과 고정 소수점 방식이 있다. 방식 이름에 ‘소수점’이 들어가서 소수만 표현하는 방식으로 생각할 수 있는데, 두 방식의 차이는 실수를 표현할 때 정수부와 소수부를 어떤식으로 나눠서 표현하는데 있다.
4-1. Fixed point
고정 소수점은 이름에서 짐작할 수 있듯이 정수부와 소수부를 나누는 소수점의 위치를 어느 한 곳으로 고정해서 쓴다는 것이다. 친숙한 10진수를 예를 들어보자. 180.7이라는 숫자가 있을 때 앞으로 소수점은 0과 7사이에 위치해있는 것으로 고정이다. 따라서 여기에 10의 거듭제곱을 곱해서 자릿수를 변동해도, 우리는 소수점이 0과 7사이에 고정되어 있다는 것을 알고 있기 때문에 정수를 나타내는 자릿수와 소수를 나타내는 자릿수를 알고 있다. 만약 180.7에 100을 곱해서 18070이 되어도, 해당 수의 정수 부분의 자릿수는 180, 그리고 소수 부분의 자릿수는 70인 것이다. 소수부분을 원래대로 복원시키려면 70에 곱해진 100을 나누면 된다.
이번엔 2진수를 가지고 1.25를 표현해보자. 1.25를 2진법으로 변환하면, 2^0 * 1 + 2^{-1} * 0 + 2^{-2} * 1 = 1.01 이다. 소수점은 정수부 1 과 소수부 01 사이에 고정되어 있다. 16bit MCU라고 가정하고 2^8을 곱해보면 (2진법 이므로 bit를 8자리 옆으로 이동시켜 주면 된다.) 0000 0001 0100 0000 가 된다. 메모리에 따로 소수점을 표시하지는 않아서 각 숫자를 16bit에 차곡차곡 넣어주면 0000 0001 0100 0000이 입력되어 정수처럼 보이지만, 정수부는 0000 0001, 소수부는 0100 0000이 되는 것이다. 10진수에서 예시를 들었던 것과 마찬가지 방식으로 2진수 역시 소수를 원래대로 복원시키려면 다시 2^8로 나눠(비트를 오른쪽으로 8칸 밀면 됨) 0.01 로 만들면 된다.
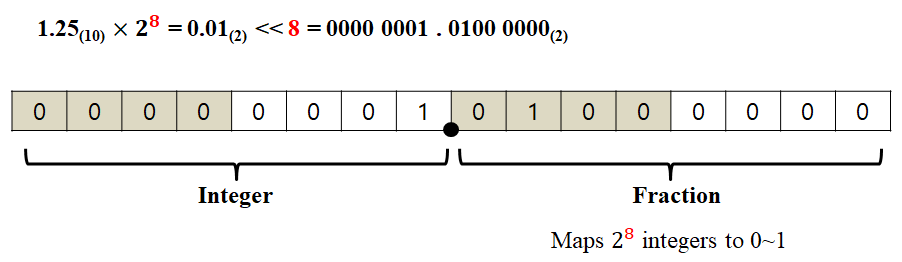
만약 $2^8$이 아니라 $2^9$를 곱했다면 소수부의 자릿수가 9칸이 되었을 것이다. 즉, 비트를 왼쪽으로 shift 할수록 더 많은 자릿수로 소수를 표현할 수 있게 되고, 더 많은 자릿수를 쓸수록 소수를 표현하는 resolution이 더 정밀해지는 효과를 볼 수 있다. 8칸인 소수부는 0부터 $2^8-1$까지의 256개의 정수가 0~1 사이의 소수로 mapping 되는 것이지만 9칸인 경우 512개의 정수로 0~1사이 소수를 표현하는 것이기 때문이다. 이를 이용하면 IEEE에서 floating point가 지정한 정밀도 보다 더욱 정밀한 자료형을 만들어서 쓸 수 있다.는 장점을 얻을 수 있다. 대신 정수부에 사용되는 자릿수가 줄어드므로, 표현할 수 있는 수의 범위 자체는 줄어든다.
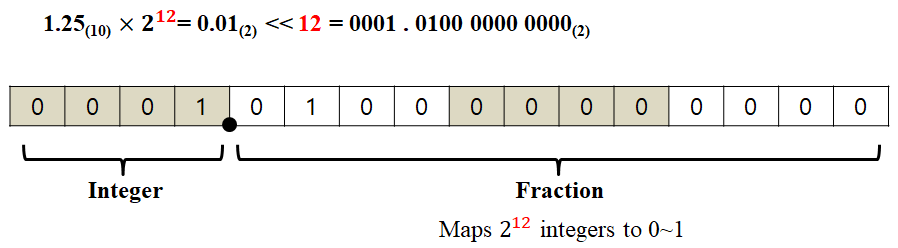
그 밖에도 고정 소수점을 사용할 때 얻어지는 다른 장점으로는 소수를 포함한 실수들을 ALU가 연산하기 쉬운 정수형 자료형으로 mapping 시킬 수 있어 연산 속도가 향상될 수 있다는 것이 있다. Floating point unit(FPU)가 없는 옛날 옛적에는 위와 같은 방식으로 사용자에 의해 정의된 고정소수점을 사용하여 실수 연산을 수행했다. 요즘에는 앞에서 언급한 장점을 살릴 때만 제한적으로 fixed point 방식이 사용된다.
4-2. Floating point
float를 한글로 번역하면 둥둥 떠다니는 것이 연상되지만, 한자로 번역되는 과정에서 ‘부동’이라고 이름이 붙여지는 바람에 ‘부동의 1위’와 같은 표현을 자주 접했던 우리에게 fixed point 보다 소수점이 더욱 확고하게 박혀있을 거라는 편견을 준다. 그러나 floating point는 영어 float가 가지는 의미처럼 소수점이 유동적으로 변한다는 뜻이다.
마찬가지로 180.7이라는 10진수를 가지고 예시를 먼저 들어보자면, 고정 소수점의 경우 0과 7 사이에 소수점이 고정된 상태이지만, 부동 소수점은 이를 $1.807 \times 10^2$ 와 같이 정수를 한 자리만 남기고 소수점의 위치를 옮기는 방식을 말한다. (0과 7사이에서 1과 8사이로 옮김) 부동 소수점 방식을 사용하면 35000, 0.00452 는 각각 $3.5 \times 10^4$, $4.52 \times 10^{-3}$ 가 된다. 2진수에서 부동소수점을 사용해서 어떤 수를 나타내면 $0.XXX \times 2^{YYY}$ 또는 $1.XXX \times 2^{YYY}$ 나타나게 될텐데, IEEE에서는 다음과 같은 형태로 부동소수점을 표현할 것으로 약속하고 있다.
\[Value = (-1)^s \times (1.m)_2 \times 2^{e-bias}\]여기서 bias 는 32bit MCU에서 127이고, 64bit MCU에서는 1203에 해당한다. bias가 왜 있는지에 대한 의문은 잠시 참고 비트에 어떤식으로 표현되어 있는지 아래의 그림을 확인해보자.
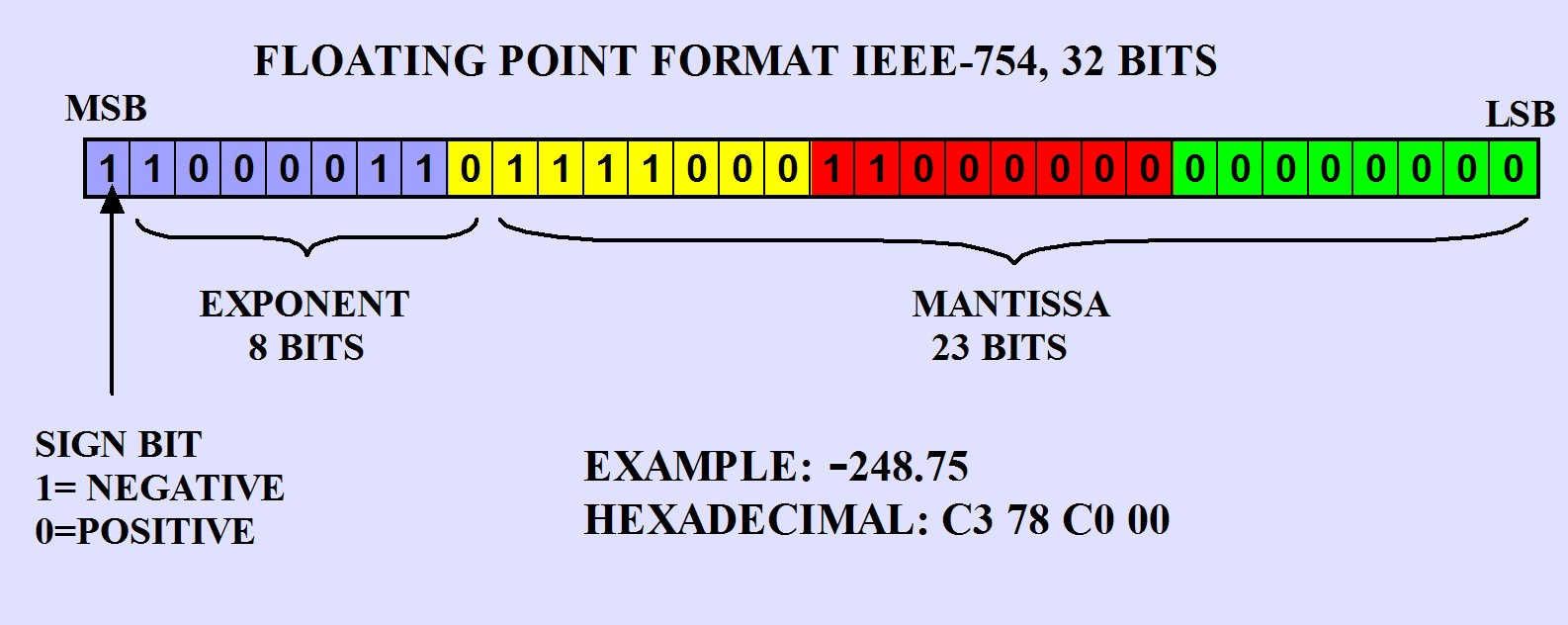
먼저 최상단 비트(MSB)에서는 integer의 부호를 나타내는 방식과 마찬가지로 표현하려는 실수가 양수인지, 음수인지를 0또는 1로 표현하게 된다. 그리고 e-bias가 exponent 비트를 차지하게 된다. 여기서 bias가 필요한 이유를 알 수 있는데, 만약에 표현하려는 부동 소수점의 지수가 음수인 경우 ($ -1 \times 1.010010_2 \times 2^{-35}$ 에서 -35를 이진수로 표현하려면?!) 이를 표현하기 위한 부호 비트가 또 필요하게 된다. 하지만 127이 bias로 빼져 있는 상태라면 0~255를 표현하는 unsigned 형태의 8bit로 -127~128 사이에 있는 지수를 표현할 수 있기 때문이다. 그리고 가수부(mantissa, 1.m 의 ‘m’)에 해당하는 소수부는 뒤의 23bit에 그대로 표현하면 된다.
가수부가 메모리 상에서 2진수로 나타나기 때문에, 만약 내가 표현하고자 하는 실수가 2의 거듭제곱의 합으로 나눠떨어지지 않는다면 이를 완벽하게 표현할 수 없다는 문제가 있으므로 주의해야 한다. 0.9만 해도 2^-1 + 2^-2 + 2^-3 + 2^-6 + … 로 비트를 가득채우며 근사치로 메모리에 저장될 뿐 실제로 0.9가 저장되는 것이 아니다. 따라서 아래 코드를 실행하면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <stdio.h>
int main()
{
float a = 0.9;
float b = 0.3;
if (1.2 == (a+b))
{
printf("yay\n");
}
else
{
printf("no. a+b is %.10f.\n",(a+b));
}
return 0;
}
1
no. a+b is 1.2000000477.
가 출력된다. 모든 경우에 위에 처럼 나오는 건 아니고 rounding error의 크기에 따라 운이 좋게 등호가 성립할 때도 있다. 중요한 것은 floating point를 사용해서 표현되는 수끼리 비교를 할 때는 등호를 쓰면 예측할 수 없는 결과가 나온다는 것이다. 만약에 MCU에 실수값에 대한 비교를 if문에 사용하고 싶다면 위의 코드처럼 1.2 == (a+b)를 할게 아니라 abs((a+b) - 1.2) < 0.001f 와 같은 방식으로 rounding error를 용인할 수 있는 수치 (0.001f)와 비교를 해야 한다.
5. Bit control
제어기와 관련된 C코드를 작성하는 경우 주변장치(peripheral, LED나 actuator 등)의 동작을 관리하기 위해 주변장치의 주소에 등록된 비트를 직접 제어해야할 경우가 생긴다. 아래 방법은 비트를 0또는 1로 설정하는 방식에 관한 것이다.
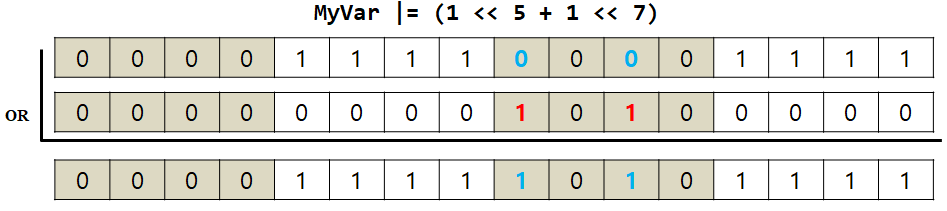
5-1. Set: Set to 1
원하는 비트에 1과 OR 연산을 하면 bit set을 할 수 있다.
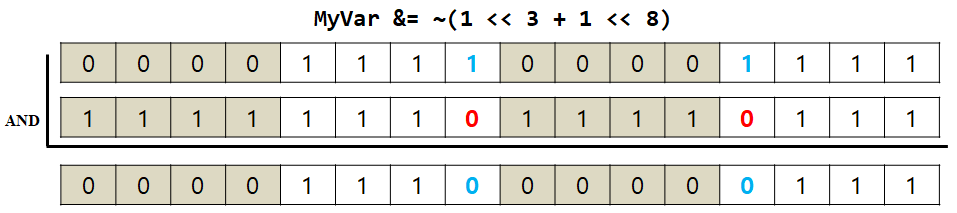
5-2. Clear: Set to 0
원하는 비트에 0과 AND 연산을 하면 bit clear를 할 수 있다. 참고로 특정 비트가 0인 데이터는 해당 비트를 1로 만든 뒤에 보수를 취하면 된다.
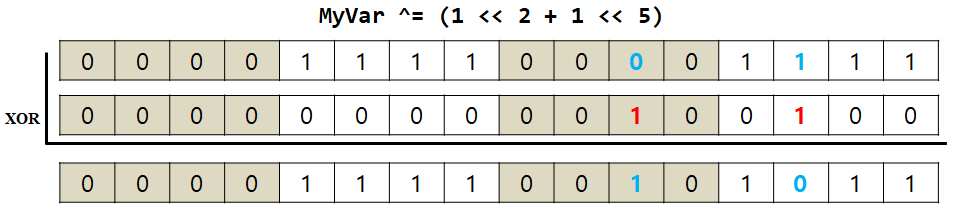
5-3. Toggle: 1 ↔ 0
원하는 비트에 1과 XOR 연산을 하면 bit toggle을 할 수 있다.
5-4. Bitfield
C에서는 struct 형 데이터 타입에 대해서 비트 단위로도 선언이 가능하다는 점을 이용해서 좀 더 직관적인 방식으로 비트를 바꿀 수 있다. 이 방식을 이해하기 위해선 아래와 같이 struct와 union을 사용해서 float형 변수에 -3.0을 입력하고 이 데이터의 sign, exponent, mantissa에 저장된 비트를 확인하는 예시를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#include <stdio.h>
#include <stdint.h>
typedef struct MyFloat // order is important
{
uint32_t mant: 23; // LSB
uint32_t exp : 8;
uint32_t sign : 1; // MSB
} MyFloat;
typedef union float_dissector {
float f;
MyFloat bit;
} float_dissector;
int main(void)
{
float_dissector s;
s.f = -3.0f;
// print bit in hex-string
printf("sign = %#x\n", s.bit.sign);
printf("exp = %#x\n", s.bit.exp);
printf("mant = %#x\n", s.bit.mant);
return 0;
}
코드에 대한 설명을 먼저 하자면, 멤버 변수인 mantissa, exponent, 그리고 sign이 차지하는 비트를 각각 설정해준 구조체 MyFloat와 float 형 변수 f가 같은 주소를 공유하도록 union 키워드를 통해 float_dissector라는 데이터 타입을 정의한 것이다.
float_dissector 형 데이터의 멤버변수인 f에 -3.0을 대입하면, 앞서 4. Decimal point의 부동소수점 부분에서 설명한 것처럼 비트가 배치되어야 한다. $-3 = (-1)^{1} \times (1.1)_{2} \times 2^{128-127} $ 이므로 sign bit와 mantissa bit는 1, exponent bit는 1000 0000이 되어야 한다. Union을 통해 주소를 공유하는 멤버변수인 bit에 담긴 값을 확인해보면, 아래와 같이 예상한 비트가 잘 담겨있는 것을 볼 수 있다.
1
2
3
sign = 0x1 // 1
exp = 0x80 // 1000 0000
mant = 0x400000 // 0100 0000 0000 0000 0000 0000
참고로, bit field에 들어있는 멤버변수 (sign, exp, mant)의 주소는 확인이 불가능하다. 왜냐하면 메모리가 byte-addressible이므로 바이트보다 작은 단위인 비트의 개별주소를 확인하는 것은 불가능하기 때문이다. 위와 같은 방식을 사용해서, 이번엔 bit field를 이용해서 주변기기(peripheral)를 제어하는 아래의 코드를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <stdio.h>
#include <stdint.h>
#include <string.h>
typedef union BitField {
uint32_t content;
uint8_t byte[4];
struct {
uint8_t b0 : 1; uint8_t b1 : 1; uint8_t b2 : 1; uint8_t b3 : 1; uint8_t b4 : 1; uint8_t b5 : 1; uint8_t b6 : 1; uint8_t b7 : 1;
uint8_t b8 : 1; uint8_t b9 : 1; uint8_t b10 : 1; uint8_t b11 : 1; uint8_t b12 : 1; uint8_t b13 : 1; uint8_t b14 : 1; uint8_t b15 : 1;
uint8_t b16 : 1; uint8_t b17 : 1; uint8_t b18 : 1; uint8_t b19 : 1; uint8_t b20 : 1; uint8_t b21 : 1; uint8_t b22 : 1; uint8_t b23 : 1;
uint8_t b24 : 1; uint8_t b25 : 1; uint8_t b26 : 1; uint8_t b27 : 1; uint8_t b28 : 1; uint8_t b29 : 1; uint8_t b30 : 1; uint8_t b31 : 1;
} bit;
} BitField;
int main(void)
{
BitField PeriA;
memset(&PeriA, 0, sizeof(BitField));
PeriA.content = 0xff00ff00; // 1111 1111 0000 0000 1111 1111 0000 0000
printf("Peripheral A's content is: %#0x\n", PeriA.content);
printf("**Byte-wise checking**:\n");
for (int i = 0; i < 4; i++)
{
printf("byte #%d: %#0x\n", i, PeriA.byte[i]);
}
// change 2nd bit, 3rd bit, and 20th bit to 1
PeriA.bit.b2 = 1U;
PeriA.bit.b3 = 1U;
PeriA.bit.b20 = 1U;
printf("\nThe content has changed to: %#0x\n", PeriA.content);
return 0;
}
위 코드는 peripheral A라는 주변기기의 비트를 컨트롤 하는 내용이며, 2번, 3번, 그리고 20번 비트를 1로 설정하는 내용이다. 위와 같이 bit field를 사용하게 되면 bit shift연산보다 훨씬 직관적인 방식으로 정교하게 비트를 설정할 수 있다. 코드의 실행 내용은 아래와 같다.
1
2
3
4
5
6
7
8
Peripheral A's content is: 0xff00ff00
**Byte-wise checking**:
byte #0: 0
byte #1: 0xff
byte #2: 0
byte #3: 0xff
The content has changed to: 0xff10ff0c
6. Pointer
Pointer 변수는 메모리의 주소를 저장하고 있는 변수이다. 컴파일러에게 해당 변수는 주소값을 가리키고 있다는 것을 알려주기 위해서 특별하게 변수명에 asterisk(별표,*)를 붙여준다. 따라서 어떤 변수를 선언할 때 *MyVar, *ThisPtr 과 같이 변수 이름 앞에 *를 붙인다면 그 변수에는 주소값이 들어있는 것이다. 그 주소가 가르키는 값이 뭔지는 포인터 변수를 선언할 때 명시를 해준다. int *MyVar, float *ThisPtr 로 선언되어 있다면 MyVar 변수 안에 들어있는 주소값은 int형을 가리키고 있으며 ThisPtr는 float형을 가리키고 있는 셈이 된다. 주소값이 가리키고 있는 저장공간에 담긴 값을 참조하려면 다시 * 연산자를 붙여주면 되는데, CPU의 입장에서는 int형 포인터 변수인 경우 주소로 부터 int의 크기에 해당하는 4바이트를 읽게 될 것이다. 예시는 아래와 같다.
1
2
3
4
int a = 3; // &a == 0x1000 이라고 하자
int *myptr = &a; // myptr 안에는 0x1000이 저장된다.
printf("a의 주소: %p\n", myptr); // 0x1000이 출력된다.
printf("a의 값: %d\n", *myptr); // 0x1000으로부터 4바이트 데이터(0x1000, 0x1001, 0x1002, 0x1003)을 읽어 3이 출력된다.
6-1. Void pointer
포인터 변수가 그저 주소(이 주소는 어떤 저장공간을 가리키고 있다.)를 담는 변수일 뿐이고, 주소가 가르키는 값은 포인터 변수가 선언될 때의 자료형의 크기 만큼을 참조해서 읽는다. 그렇다면 void형으로 선언된 포인터 변수는 무슨 의미를 가질까? 주소를 담는 변수이긴 하지만, 아직 이 주소로부터 몇 바이트를 읽을지 정해지지 않은 포인터 변수이다.
그렇다면 *를 사용해서 참조하려고 할 때 얼마만큼의 바이트를 읽도록 해야될까? 그 크기가 정해져있지 않기 때문에 void형 포인터 변수를 단순하게 * 로 참조하려고 하면 컴파일 오류가 난다. CPU 입장에서는 어떤 자로형의 데이터를 가리키는지 알 길이 없기 때문이다. 따라서 사용자가 형변환을 통해서 정해주며, 이렇게 사용자가 형변환을 통해서 얼만큼 읽을 지 정해줄 수 있다는 점에서 장점을 가진다. void 형 포인터 변수가 사용되는 대표적인 예시로 동적할당에 해당하는 malloc이 있다. 아래에서 볼 수 있다시피 malloc의 경우 void pointer를 반환하기 때문에 int 형 포인터 변수에 값을 할당하기 위해 (int *)로 typecast 하는 것을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <stdio.h>
void main()
{
int* arr; // 크기가 정해져 있지 않은 배열의 시작 주소 설정
arr = (int*)malloc(sizeof(int) * 4); // 4개의 int를 담도록 동적할당
arr[0] = 100;
arr[1] = 200;
arr[2] = 300;
arr[3] = 400;
for (int i = 0; i < 4; i++) {
printf("arr[%d] : %d\n", i, arr[i]);
}
free(arr); //동적할당 해제
}
밑의 그림과 같이 reddit에 돌아다니는 포인터 관련 meme을 보면, 앞에서 설명한 내용 뿐만 아니라 const 키워드와 같이 사용할 때의 의미까지 음미해볼 수 있다.
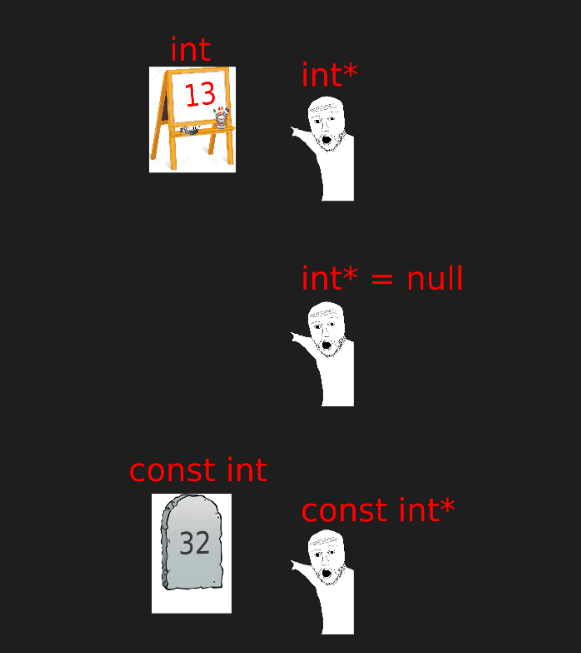 캔버스와 달리 석판에 새겨진 내용은 바꿀 수 없다.
캔버스와 달리 석판에 새겨진 내용은 바꿀 수 없다.
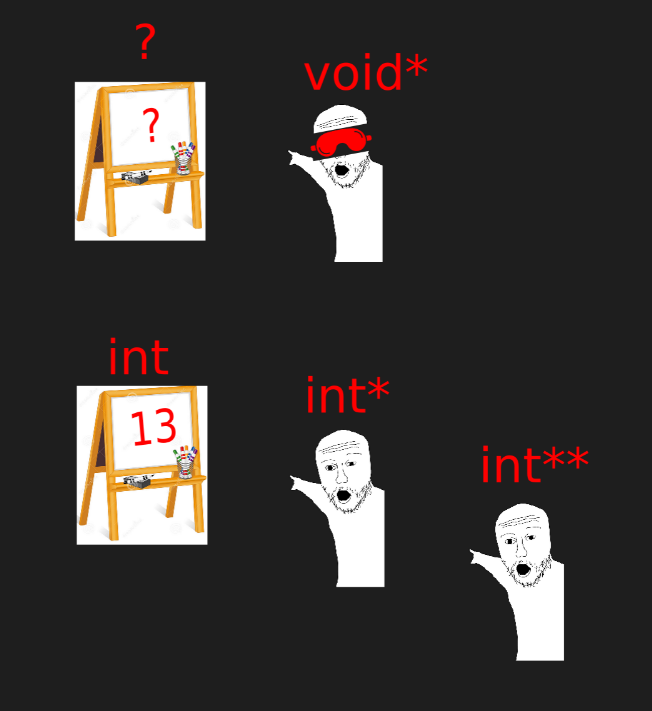 void 형 포인터는 내가 가리킬 주소는 알아도 뭘 가리키고 있는지 모른다.
void 형 포인터는 내가 가리킬 주소는 알아도 뭘 가리키고 있는지 모른다.
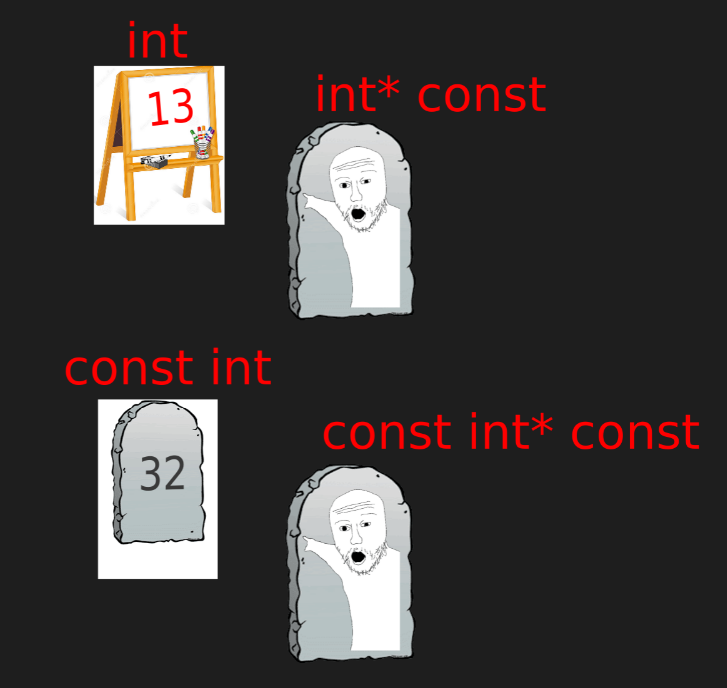
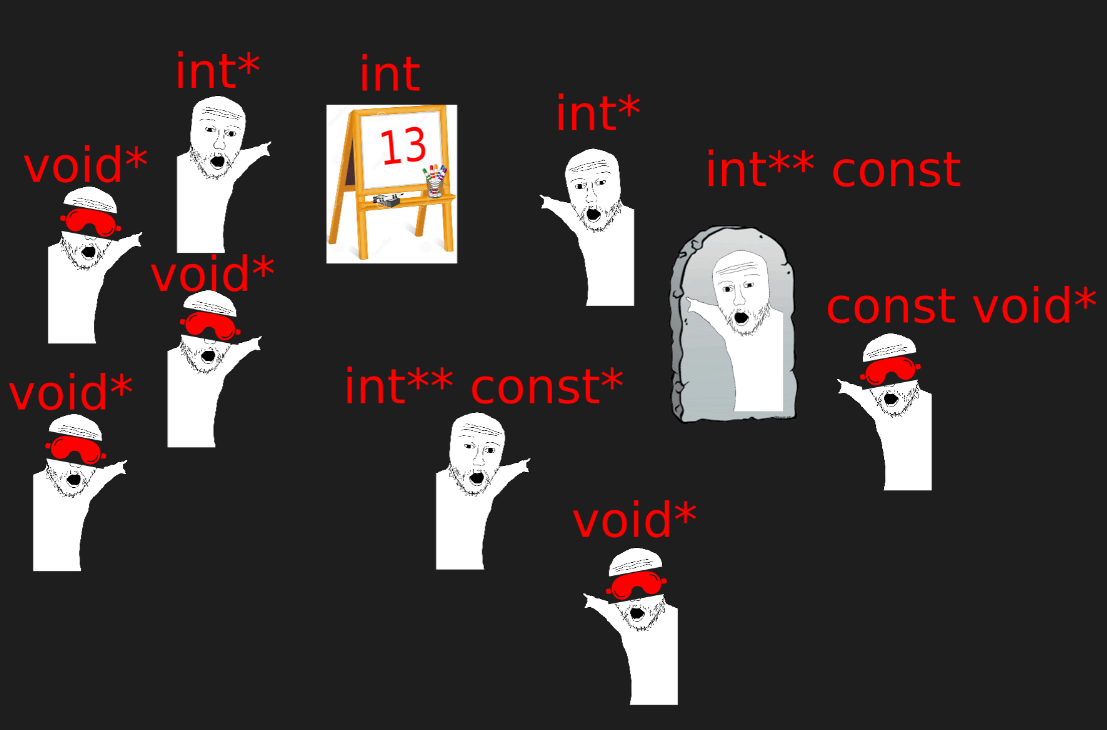 포인터를 이 정도로 변태같이 쓸 일은 없긴 하다.
포인터를 이 정도로 변태같이 쓸 일은 없긴 하다.
6-2. Function pointer
함수 이름도 변수다! 이는 우리가 main 함수 위에 간단한 함수를 정의하고 나서 main 함수 내에 별도의 작업 없이 바로 사용할 수 있다는 점에서 마치 전역 변수처럼 행동한다는 점에서 유추할 수 있다. 변수라면 역시 어느 주소값을 쓰고 있을 것이며, 이를 가리키는 포인터 변수를 만들 수 있다. 다만, 함수를 선언할 때 매개변수의 자료형을 같이 고려하는 것 처럼 함수를 가리키는 포인터 변수를 만들 때도 매개변수의 자료형도 같이 고려해줘야 한다. 함수 포인터의 예시는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <stdio.h>
int mario_jump(int, int);
int mario_superjump(int, int);
int main()
{
int mushroom = 0; // 버섯 먹었나?
int start = 0; // 시작 높이
int deltah = 1; // 점프력 (1)
int(*JUMP)(int, int); // 함수 포인터 선언 시 함수 이름에 괄호치도록 주의
printf("Initial height: %d\n\n",start);
for (int jumpcnt = 0; jumpcnt < 2; ++jumpcnt)
{
if (mushroom) JUMP = mario_superjump;
else JUMP = mario_jump;
start = JUMP(start,deltah);
printf("Height after jump: %d\n\n",start);
mushroom++;
}
return 0;
}
int mario_jump(int a, int b)
{
printf("small jump\n");
return a + b;
}
int mario_superjump(int a, int b)
{
printf("Big jump!!\n");
return a + b*3;
}
결과는 아래와 같다.
1
2
3
4
5
6
7
Initial height: 0
small jump
Height after jump: 1
Big jump!!
Height after jump: 4
이런 생각을 할 수도 있다. ‘아니 그냥 if else로 함수 두 개를 사용하면 되는거 아닌가?’ 맞는 말이다. 실제로 함수 포인터를 사용할 예시는 그렇게 많지 않다. 다만 인터페이스를 구축할 때 사용을 고려해볼 수 있다. 개발자가 위의 마리오 점프 예시처럼 구체적인 구현 내용은 다르지만 반환형과 매개변수가 같은 비스무리한 버전의 함수들을 관리한다고 할 때, 경우에 따라 하나의 함수포인터 변수에 이를 할당하면 사용자 입장에서는 함수의 버전이 바뀔 때마다 새로운 이름의 함수를 사용하는 것이 아니라 기존에 사용하던 함수 포인터를 계속 사용할 수 있다는 장점이 있다.


Leave a comment