Embedded C_Lecture 1
Micro Controller Unit (MCU) 개요
Microco Controller Unit(MCU)는 micro processor(core or CPU), 메모리, 입/출력(I/O or peripheral) 을 통합한 집적 회로 (integrated circuit, IC)를 의미한다. PC에 들어가는 범용 microprocessor와는 약간 다른데, 그 이유는 하드웨어 부속품을 제어하는데 최적화되어있기 때문이다. 보통 실시간(real time)성이 필요하고 저전력으로 효율적인 솔루션이 필요한 곳에 많이 사용된다. MCU를 이루는 CPU, memory, peripheral는 쉽게 연산하는 장치, 기록하는 장치, 그리고 외부로 데이터를 송/수신 하는 장치로 생각하면 된다.
1. Central Processing Unit (CPU)
Central Processing Unit(CPU)는 메모리에 기록된 데이터를 다루기 위한 각종 지시사항(Instruction)과 대수적인 연산(Arithmetic logic)을 수행하고, 이 연산의 중간 과정이나 결과를 기록하기 위한 Register로 이루어져 있다. CPU라고 하면 어떤 정형화된 물리적인 단위는 아니고 레지스터를 포함하여 이러한 연산을 수행하는 장치들을 포함한 것을 의미한다.
CPU의 경우 ARM(Advanced RISC Machine)社의 architecture를 기반으로 삼성전자, 애플이 SOC를 설계하고, TSMC 등에 의해 외주를 맡기는 식으로 양산된다. 특히 CPU에 부가적인 기능을 추가한 형태로 모바일용 CPU인 application processor(AP)의 경우 ARM이 독점하고 있으며 이와 관련된 내용은 여기에 설명이 잘 되어있다.
1-1. Instruction Set Architecture (ISA)
Instruction Set Architecture(ISA)는 CPU에서 데이터를 연산하기 위한 사용자 인터페이스를 말한다. 인터페이스는 연산자(operationn)과 피연산자(operand)로 이루어져있으며, 짤막하게 살펴보면 아래와 같이 분류될 수 있다.
1-1-1. Operation
- Math and logical : Add, Subtract, Multiply, Divde, AND, OR, XOR, …
- Shift/Rotate(비트이동) : Logical Shift Right, Logical Shift Left, Rotate Right, Rotate Left, …
- Load/Store(메모리연산) : Load, Store, …
- Branch operation : Compare Instructuions, Move Instructions, …
1-1-2. Operand
MCU의 레지스터 주소값이 된다. MCU의 경우 byte-addressible memory로 보통 주소를 1바이트 단위로 매기는데, 레지스터의 경우 4바이트(32bit)의 크기를 가지므로 레지스터 주소끼리는 4바이트씩 차이가 난다.
참고로 보통 레지스터에 의해 한 번에 읽고 처리할 수 있는 데이터의 사이즈가 X bit인 경우 Xbit를 1 word로 하며 X-bit microprocessor라고 부르는데, 32bit microprocessor를 오랫동안 쓰면서 1 word = 32 bit로 굳어졌다. 만약 16bit register를 사용하는 MCU라면 1 word = 16 bit이며 레지스터간 주소 차이는 2byte씩 나게 된다.
Operation과 operand로 이루어지는 Instruction set 의 아주 간단한 예시로는 ADD R0, R1, R2가 있다. 이는 R1과 R2가 가리키는 값을 더해서 R0에 대입하라는 뜻이다. 레지스터에 있는 Program Counter(PC)가 연산 수행 이후 4byte 씩 증가한 주소를 저장하게 되는데(레지스터가 다루는 데이터의 단위가 4byte이므로), CPU는 메모리 상에서 PC가 가리키는 주소를 참조하여 해당 주소에 적혀있는 instruction을 따르는 작업을 반복할 뿐이다. 메모리에 저장되어 있는 Instruction은 당연히 binary 형태로 encoding 되어 있으며, 이런 encoding 결과를 opcodes라고 한다. (0001이면 add, 0010이면 AND, etc.)
1-1-3. Byte ordering
이렇게 MCU의 레지스터는 주소가 4byte 단위이지만 메모리의 주소는 1byte 단위이기 때문에, 레지스터의 값을 메모리에 옮길 때 사소한 문제가 생긴다. 바로 옮겨적는 값의 제일 작은 자리수(Least Significant Bit, LSB)와 제일 큰 자리수(Most Significant Bit, MSB)를 어떤 순서로 옮겨 적는지의 문제이다.
예를 들어 0x12345678과 같은 16진수를 보자. 제일 작은 자리수는 8이고(16진법에서 16^0의 자리수) 제일 큰 자리수는 1(16진법에서 16^7의 자리수)이다. 메모리는 1byte(8bit) 단위므로, 주어진 0x12345678을 8bit로 쪼개본다. 8bit의 경우 표현할 수 있는 수의 범위가 0~(2^8-1) 이다. 힌퍈 16진수에서 두자리수가 가지는 범위는 0~(16^2-1 == 2^8-1) 이다. 따라서 0x12345678을 두자리씩 끊어서 메모리에 저장하면 되는 것이다!
두자리씩 끊으면 0x12, 0x34, 0x56, 0x78 이 나오므로 1byte로 나뉘어진 메모리를 연속적으로 4칸 차지하게 되는 셈인데, 연속된 메모리 주소를 100, 101, 102, 103이라고 하자. 제일 작은 자리수에 해당하는 0x78부터 제일 낮은 메모리 주소(100)에 차례대로 채워서 0x78(100), 0x56(101), 0x34(102), 0x12(103) 처럼 채우는 방식을 Little-Endian이라고 한다. 반면 제일 큰 자리수를 제일 낮은 메모리 주소에 차례대로 채워서 0x12(100), 0x34(101), 0x56(102), 0x78(103) 처럼 채우는 방식을 Big-Endian이라고 한다.
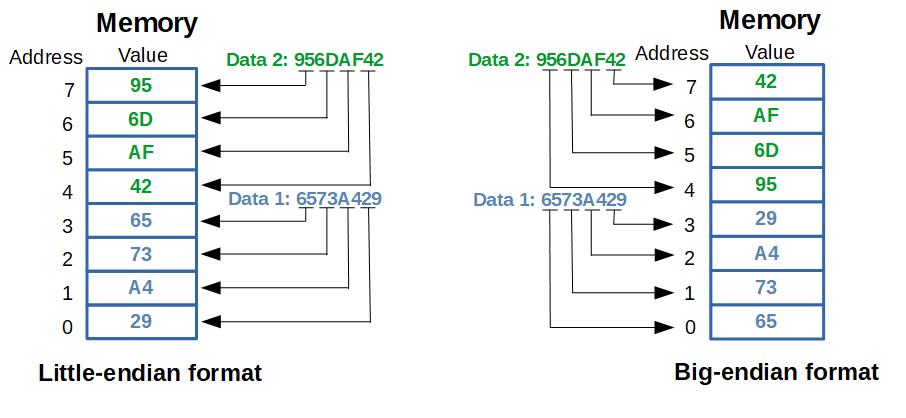
MCU는 원래 Big-Endian을 사용했지만 Intel이 Little-Endian을 도입하면서 두 체계가 공존하게 되었다. 하지만 인터넷 서버는 모두 Big-endian 기반으로 동작하기 때문에 인터넷 서버와 통신하려면 자신이 사용하는 MCU가 Little-Endian인건 아닌지 주의해야 한다.
1-2. Interrupt
Interrupt는 사용자가 의도하지 않은 unintended exception, 사용자가 의도한 intended exception(Interrupt), 그리고 운영체제가 사용하는 s/w interrupt가 있다. Uninteded exception의 경우 다음과 같다. 만약에 CPU가 Program Counter(PC)이 가리키는 주소를 참조했을 때 어떠한 이유이든 간에(개발자가 memcpy나 memset과 같이 주소를 참조하는 코드를 잘못 짜거나 배열을 잘못 참조하는 등) opcodes로 encoding 할 수 없는 binary가 들어있는 경우를 일컫는다. 보통 이런 경우 s/w trap이 발생했다고 하며 MCU가 초기화 되곤 한다. (뻗는다고 표현함)
Intended exception(Interrupt)의 경우 입출력 장치에 의한 데이터 수신이 대표적인 예시가 되며, Nested Vectored Interrupt Controller(NVIC)와 같은 하드웨어 장치에 관리가 된다. 만약 interrupt를 감지하는 경우 CPU의 context(마지막 PC값, register 값)가 백업된 뒤 NVIC에 의해 CPU의 PC값이 가리키는 주소를 바뀌고, 해당 instruction이 먼저 수행된다. Interrupt에 의해 PC가 어떤 주소를 가리킬 지는 vector table에 미리 정의가 된다.
2. Memory

메모리는 휘발성인 random access memory(RAM)과 비휘발성인 read only memory(ROM)으로 나뉜다. 보통 비휘발성 메모리인 ROM이 장기 기억 장치인 secondary memory로 사용되며, 휘발성 메모리인 RAM이 CPU가 접근하여 연산의 중간 과정을 임시로 기록하는 main memory로 사용된다. RAM의 이름이 random access memory인 이유는 컴퓨터가 처음으로 만들어졌을 시절 메모리에 접근하는 방식이 자기테이프를 이용한 sequential 형태란 점에서 유래되었다.(sequential access memory) 따라서 메모리상 어느 공간에 접근하기 위해서는 마치 카세트 테이프를 돌리는 것 처럼 순차적인 탐색이 필요했다. 그러나 전기적인 신호를 통해 0과 1을 표현할 수 있는 회로로 구성된 메모리가 등장하면서, 랜덤한 메모리에 바로 접근하는 것이 가능하게 되었다.
ROM의 경우 첫 등장 당시 이름인 read only memory에 충실하게 읽기만 가능한 저장소였다. 칩을 만들 때 photomask를 통해 etching을 적용하여 회로상에 연결된 곳과 끊어진 곳으로 0과 1을 표현해 정보를 저장한 것이 ROM의 시초이다. 그 후 모든 회로가 연결되어 있는 칩에 필요한 부분만 강한 전압을 걸어 0과 1을 구현한 one-time programmabel ROM(OTP ROM, 또는 PROM이라고 불림)이 등장했고, 나중에는 UV를 쬐어 여러번 수정이 가능한 형태의 EPROM이 등장했다. 그러나 현대로 와서 ROM, PROM, EPROM은 거의 쓰이지 않고 이제는 FLASH와 EEPROM이 쓰이고 있다. FLASH와 EEPROM의 경우 사실상 여러 번 수정이 가능하기 때문에 더이상 Read Only Memory라 부르기 애매한 존재가 됬다. 따라서 이제 RAM과 ROM은 전원이 있을 때 정보가 유지, 삭제 되는지를 설명하는 휘발성/비휘발성을 가지고 구분한다.
모든 데이터는 메모리를 이루고 있는 Bit-Cell(cell)에 전압이 있는지/없는지로 구분하여 binary(0또는 1) 형태로 저장된다. Cell 당 1비트의 데이터를 저장할 수 있으므로, 단순히 계산만 하자면 4GB = 4 * 10^9 * 8 bit의 메모리에는 4 * 10^9 * 8개의 cell 이 물리적으로 구현되어 있는 것이다. 요즘 나오는 반도체의 집적도를 높이기 위해 하나의 셀에도 여러 개의 비트를 저장할 수 있다. 단일 셀에 여러 비트를 저장하는 방식에 관한 자세한 내용은 sk hynix 블로그를 확인해보자.
2-1. Volatile Memory
휘발성 메모리인 RAM은 static RAM(SRAM)과 dynamic RAM(DRAM)으로 나뉜다. 둘의 차이는 회로의 구성 방식에 기인하는데, 먼저 DRAM은 1개의 transistor와 1개의 capacitor로 이루어진 단순한 형태의 memory cell로 구성되어 있다. 전압이 걸려서 capacitor에 전하가 충전된 상태가 2진수의 1을 표현하고, 방전된 상태로 0을 표현한다. capacitor가 충/방전 되는데 시간이 지연되기 때문에 DRAM에 데이터를 기록하는데 수백ns~수백us 정도의 지연시간이 걸리게 된다. 또한 내부저항에 의해 시간이 지나면(대략 20ms) 자연적으로 방전되는 문제가 있어 Refresh circuit이라는 회로로 전압을 유지한다. DRAM은 삼성전자와 hynix가 강점을 가지고 있는 제품군으로 알려져 있다.
반면 SRAM은 MOSFET이라는 트랜지스터 6개를 활용하여 전하를 가두는 특별한 형태의 회로로 memory cell을 구현하기 때문에 전하의 손실이 적어 refresh circuit이 필요 없다. 대신에 애초에 memory cell을 구성하는데 있어 소자가 더 많이 사용되기 때문에 DRAM보다 가격이 비싸다. 그러나 capacitor를 사용하지 않아 충/방전 지연시간이 없기 때문에 데이터를 저장하는 속도가 DRAM보다 빠르며, 이러한 빠른 속도 때문에 CPU내에 있는 register와 main memory 사이에 나타나는 속도 간극을 줄이기 위한 cache를 SRAM으로 구현한다. 참고로 cache란 main memory로부터 자주 참조되는 데이터와 그 주변의 데이터를 저장하는 공간으로, pipeline, multicore와 더불어 micro processor의 성능이 quantum jump할 수 있었던 세 가지 요인 중 하나이다.
cache memory에 대한 설명을 좀 더 하자면, 별도의 고정된 address space를 가지지 않고 main memory로부터 자주 사용되는 데이터의 주소를 복사하여 가지고 있는 형태이다. main memory의 주소를 cache memory로 mapping 시키는 방식에도 direct mapping/associative mapping/set associative mapping과 같이 다양한 형태의 방식이 존재하는데, 이는 여기를 참고하도록 하자. 만약 CPU가 Program Counter가 가리키는 주소에 있는 연산을 수행하는데 어떤 데이터가 필요하다면, 먼저 cache memory를 살피면서 해당 데이터가 있는지 탐색하게 되고, (있다면 이를 hit, 없으면 miss라고 한다.) 없는 경우에만 main memory에서 가져오도록 한다. 탐색과정이 이루어지므로 cache memory는 클수록 비효율적이며, 따라서 메모리가 클수록 cache를 키우는게 아니라 multi level로 이루어진 cache를 사용한다.
2-2. Nonvolatile Memory
현재 비휘발성 메모리는 크게 Flash 와 EEPROM으로 나뉜다. 둘의 차이는 가격과 수명으로 나눌 수 있는데, 보통 Flash가 EEPROM보다 저렴한 대신 수명은 긴 편이다. 수명이 짧다는 것은 메모리 내 데이터를 지우고 다시 쓰는 것을 반복할 때 이를 어느정도로 견딜 수 있는 지를 말하는 것이며 보통 Flash의 경우 100만 번정도, EEPROM의 경우 10만 번 정도 데이터를 지웠다가 다시 쓸 수 있다. 따라서 OTA와 같이 소프트웨어를 업데이트하는 경우 업데이트 된 소프트웨어 코드는 Flash 메모리에 기록되고, 운영하는 시스템의 전원이 차단될 때마다 기억되야 하는 소규모의 데이터들은 EEPROM에 기록된다.
또한 Flash는 NAND flash와 NOR flash로 구분되는데, NOR flash의 경우 RAM과 같이 byte addressible(접근할 수 있는 최소 단위의 메모리가 1바이트) 한 형태라서 CPU가 데이터에 바로 접근할 수 있는 장점을 가지고 있다. 따라서 MCU와 같이 메인 메모리가 너무 작은 경우 secondary memory로 NOR flash를 사용하여 기록된 데이터를 CPU가 직접 접근할 수 있도록 구성하기도 한다. 일반 PC는 secondary memory로 NAND flash를 사용하며, NAND flash는 byte addressible 하지 않기 때문에 여기에 있는 데이터를 처리하기 위해서는 먼저 main memory로 옮기고 주소가 부여되고 나야 CPU가 처리할 수 있게 된다.
2-3. BUS
데이터 통신을 위한 회로인 bus도 메모리와 연관이 있다. 왜냐하면, 메모리가 커봤자 bus가 작으면 한번에 송/수신할 수 있는 데이터가 bus의 용량에 의해 제한되기 때문이다. 주소값이 전달되는 Address bus의 경우 이는 곧 사용할 수 있는 메모리의 양을 의미한다. 왜냐하면 Address bus가 32비트 방식(32줄의 wire)인 경우 한 번에 2^32개의 주소를 표현할 수 있으며, byte addressible이기 때문에 2^32개의 주소는 2^32바이트 = 4GB의 공간을 한 번에 access할 수 있음을 뜻한다. 따라서 만약 내가 사용하는 PC의 address bus가 32bit 방식이라면, 단일 bit를 저장하는 메모리 cell의 갯수가 아무리 많더라도 현재 가용할 수 있는 메모리는 4GB이다. 그렇다고 물리적으로 남는 메모리는 버려지는 것은 아니고, paging이라는 기법을 통해 memory management unit(MMU) 가 가상 메모리를 설정해서 남는 물리적인 메모리에 접근할 수 있게 해준다.
3. Peripheral
MCU의 각종 입/출력을 담당하는 주변장치(peripheral)은 peripheral controller processor에 의해 통합 관리되며, 이 processor 는 control register, status register, 그리고 data register를 포함하며, 각 register들의 숫자는 configuration에 따라 가변적으로 운용된다. Control Register는 주변 장치를 제어하기 위한 설정을 저장하는 레지스터로, CPU는 이 레지스터를 통해 주변장치의 동작을 제어할 수 있다. Status register는 주변 장치의 상태 정보를 저장하는 레지스터로, CPU는 이 레지스터를 통해 주변장치의 상태를 확인할 수 있다. 마지막으로 Data register는 주변장치와 교환할 데이터를 저장한 레지스터이다. CPU는 이 레지스터를 통해 데이터를 주변장치로 보낼 수 있고, 주변 장치로 부터 데이터를 읽어올 수도 있다.
3-1. CPU-Peripheral Methodology
CPU가 Peripheral과 데이터를 주고 받으며 통신하는데는 여러가지 방법론이 있다. 먼저 데이터 전송에 관한 방법론으로 Memory-mapped IO와 Isolated IO가 있다. Memory-mapped IO는 main memory 상에 peripheral을 위한 주소 공간을 할당하는 방식으로, 제일 많이 쓰이는 방법론이다. 따라서 Peripheral이 할당된 주소 공간을 알고 있다면, 주소에 access하여 데이터를 변경하는 코드를 작성할 수 있다. 반대로 Isolated IO는 peripheral의 주소 공간이 memory내 주소와는 독립적으로 운영이 된다. 대표적인 Peripheral인 display는 pixel 하나하나에 대해서 i/o를 제어해야 한다. 1초에 60번씩 모든 pixel에 대해서 I/O 주소가 참조되며 많은 연산이 동반되는 peripheral인 셈이다. 만약 PC에서 display를 제어하기 위해 memory-mapped IO를 사용한다면 main memory의 1GB 정도를 차지할 정도로 많은 메모리가 필요하다. 따라서 이 때는 Isolated IO를 사용하는 편이 좋다고 한다.
Peripheral이 CPU에 접근하는 방식으로는 Polling IO와 Interrupt-driven IO가 있다. Polling IO의 경우 CPU가 계속 peripheral processor 내의 status register를 지속적으로 확인하는 방식이고, interrupt-driven IO는 NVIC와 같은 H/W를 통해 CPU에게 interrupt를 발생시는 방식이다.
CPU가 Peripheral를 제어하는 방식으로는 Program-controlled IO와 DMA(Direct Memory Acess) 방식이 있다. CPU가 관여하는 program-controlled IO와 달리 DMA는 Memory에서 Peripheral을 직접 제어한다.
3-2. Peripheral Elements
대표적인 Peripheral로는 CPU의 clock을 세는 timer, 모터 속도 제어 및 LED 밝기 조절 등에 사용되는 PWM(Pulse-Width Modulation), 그리고 아날로그 신호를 디지털로 전환하는 ADC(Analog to Digital Convertor) 등이 있다. Timer의 경우 보통 MCU당 80개 정도를 가지고 있으며, 1MHz의 CPU의 경우 1 clock 당 1us씩 counting 하는 방식으로 동작한다. PWM에서는 Digital 신호의 펄스폭을 조절하는 장치로, 펄스의 몇 %가 high 값인지를 나타내는 duty를 조절하여 LED를 살짝 어둡게 하거나 actuator의 출력을 변경할 수 있다. ADC의 경우 소리와 같은 아날로그 신호를 sampling(시간에 대한 discretize, 보통 아날로그 주기의 2배로 sampling), quantization(y축 discretize) 그리고 coding 과정을 거쳐서 디지털 신호로 변환한다. 참고로 하나의 기기에 여러 Peripheral들이 slave 형태로 붙어 있는 경우 SPI나 I2C와 같은 형태의 통신 프로토콜을 사용한다.
4. Computer Architecture
앞에서 설명한 CPU, Memory, 그리고 Peripheral들로 이루어진 컴퓨터의 architecture은 아래 그림과 같이 두 가지 방식으로 나뉜다.
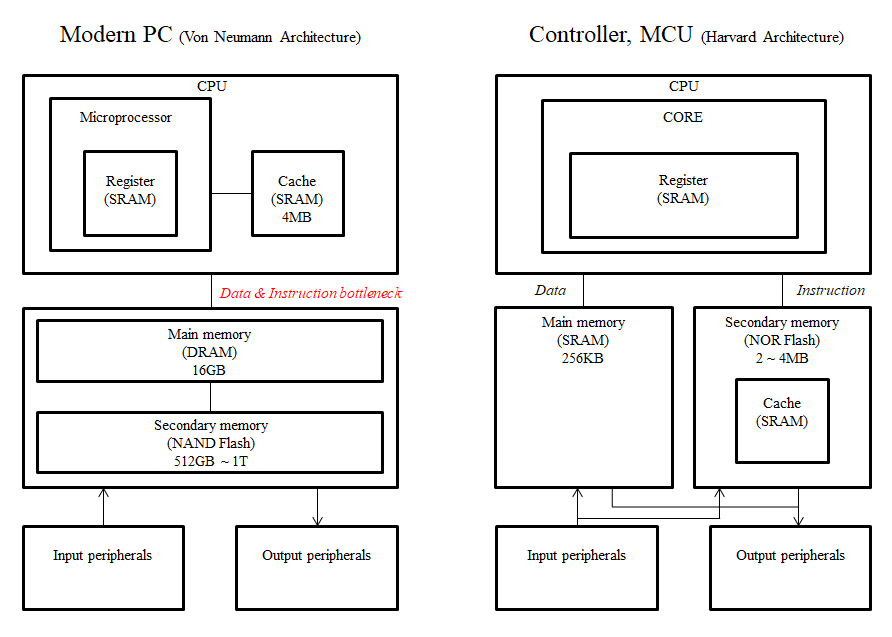
CPU가 main memory에만 접근할 수 있는(Von Neumann architecture) 일반 가정용 컴퓨터와 달리 제어기나 MCU는 Harvard architecture을 따르기 때문에 main memory 뿐만 아니라 secondary memory도 직접 접근할 수 있는 구조로 되어 있어 data와 instruction을 동시에 읽는데 문제가 없다. 또한 main memory가 256KB로 PC에 비해 매우 작은편이라 비용적인 측면에서 SRAM으로 구성이 가능하다. SRAM의 데이터를 읽고 쓰는 속도는 빠른 편이므로 PC와는 다르게 CPU에 접근하는데 있어 별도의 cache memory를 거치지 않는다.
위 그림에는 CORE가 1개인 MCU로 묘사되어 있는데, MultiCore MCU도 많다. 대표적으로 Infineon 社의 TriCore는 이름에서 알 수 있듯이 3개의 코어를 사용한다. 세 코어는 하나의 main memory를 공유하는 구조로 architecture가 설계되어 있으며, 이런 경우 core 간 데이터 충돌을 방지하기 위해 SPM (Scratch-pad memory)를 사용한다. 이는 CPU 상의 레지스터와 메인 메모리 사이에 위치하며, 마치 cache memory 처럼 자주 사용되는 데이터를 관리하는 저장소이다. 그러나 하드웨어에 의해 관리되는 cache memory와는 달리 SPM은 개발자가 직접 소프트웨어 상에서 데이터를 관리할 수 있는 programmable 한 형태를 띈다. cache를 사용할 경우 execution time이 determinisitic 하지 않아 성능을 예측하기 힘들기 때문에 MCU에서는 주로 SPM을 cache 대신 사용한다.


Leave a comment