Deep Learning Lecture3 - DeepLearning by Convolutional Neural Network
Convolutional Neural Network
지난 포스트1와 포스트2를 통해 Perceptron의 작동 원리 및 다층 perceptron을 통한 deep learning 테크닉 들을 살펴보았다. 이번엔 이미지 내 객체 인식에 초점을 맞춘 Convolutional Neural Network 알고리즘을 살펴보고자 한다.
Architecture
Convolutional Nerual Network는 이미지 내 패턴을 학습시키는 모델로, 기존 Multilayer Perceptron 구조에서 Convolution layer를 추가한 형태이다. CNN의 구조는 다음과 같다.
- input 데이터와 kernel matrix와의 convolution 곱으로 1차적인 패턴을 파악한다.
- Pooling을 통해 축소된 차원의 데이터를 얻는다.
- 파악된 패턴을 input data로 하여 1~2의 구조를 추가한다. (반복할 수록 고차원적 패턴을 인식)
- 최종적인 고차원 패턴을 fully conected 구조인 layer에 통과시켜 loss function을 구한다.
- loss function이 최소화 될때 까지 1~4를 반복한다.
Kernel Matrix
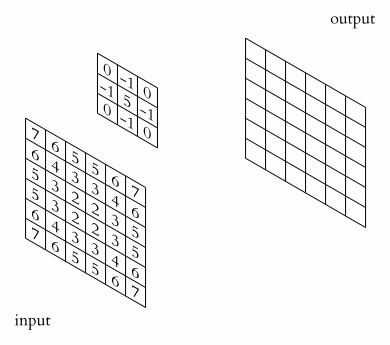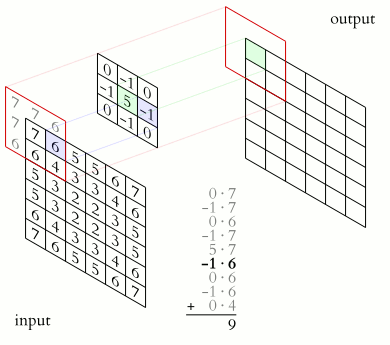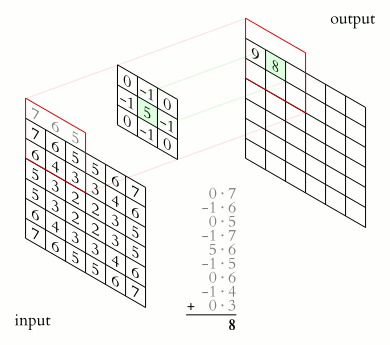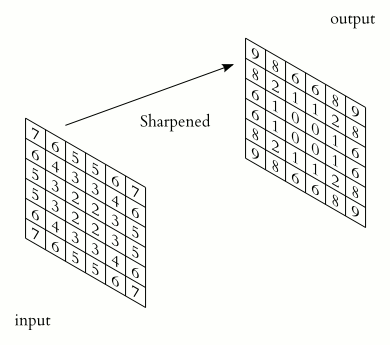
kernel matrix와 input 데이터의 convolution곱은 아래 그림을 통해 확인할 수 있다.
 reference:towardsdatascience
reference:towardsdatascience
convolution 곱은 어려운게 아니라 사용자가 임의로 설계한 크기의 kernel matrix (그림에선 3x3, kernel matrix의 초기값은 보통 0~1사이값으로 random하게 설정.) 와 input data를 element-wise로 곱한 뒤 더한 값일 뿐이다. 만약에 input data가 이미지라면 각 픽셀 값이 0~255 사이의 값을 가지는 2D array로 표현 될 것이다. (물론 0~1사이 값을 가지도록 normalize 시킨 후 learning 을 시작한다.)
다만 같은 input 데이터에 대해서도 kernel matrix가 여러 개 존재한다면 각 kernel matrix의 생김새에 따라 여러 개의 output 이 나올 것이라고 유추할 수 있다. 예를 들어 kernel matrix가 대각 성분만 1이고 나머지 성분이 0이라면, 이미지에서 대각 성분이 나타나는 곳은 convolution 곱에 의해 activation map 상에서 큰 값을 가지게 될 것이다. 아래 그림을 보자.
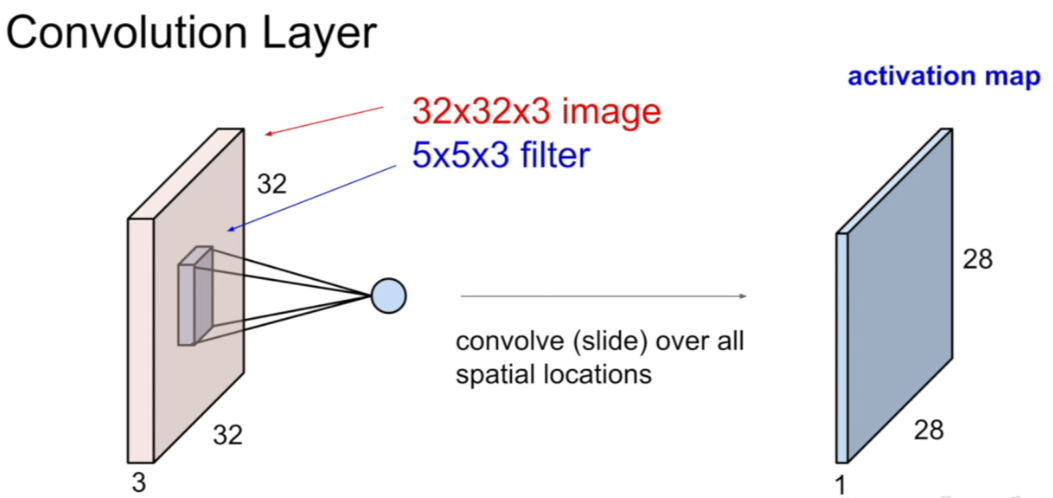 reference:Youtube-StanfordUniversity
reference:Youtube-StanfordUniversity
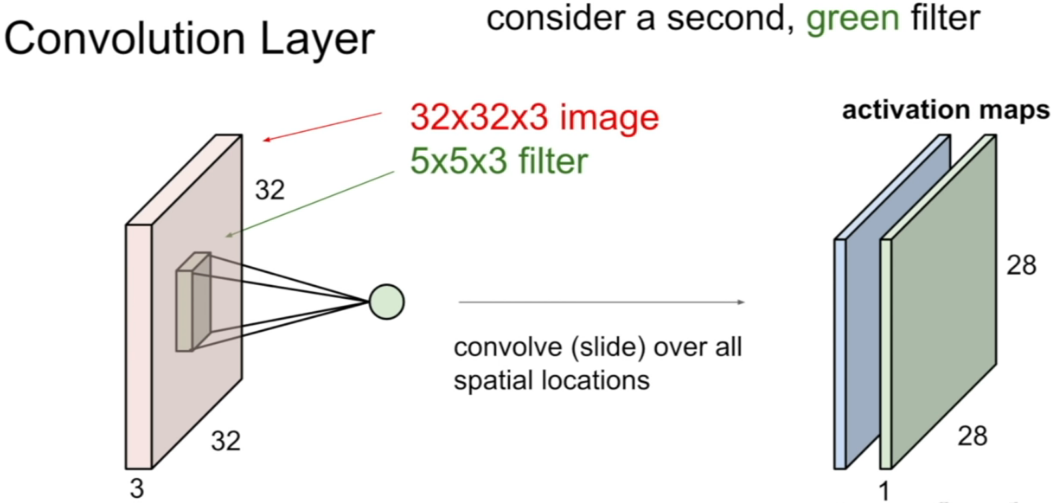 reference:Youtube-StanfordUniversity
reference:Youtube-StanfordUniversity
위 그림은 32x32 사이즈의 이미지가 R,G,B 세 개의 값을 가지는 픽셀로 표현됬을 때를 input으로 하는 경우이다. 5x5x3 크기의 kernel matrix와 input data를 convolution 곱을 하면 28x28x1 사이즈의 결과물이 나오고, 보통 이를 activation map 이라고 한다. (가로 세로 크기가 28로 줄어든 이유는 input data 경계면 바깥으로는 계산을 하지 않았기 때문이다. 경계면 바깥을 0으로 가정하여 데이터를 얻는 기법을 zero padding이라고 한다. zero padding을 하는 경우 32x32 크기의 activation map을 얻을 수 있다.)
위 그림 중 두 번째 그림과 같이 다른 kernel matrix (초록색 filter)를 적용하면 또 다른 결과값이 activation map이 형성될 것이다. kernel matrix가 6종류인 경우 아래의 그림처럼 결과물이 형성될 것이다.
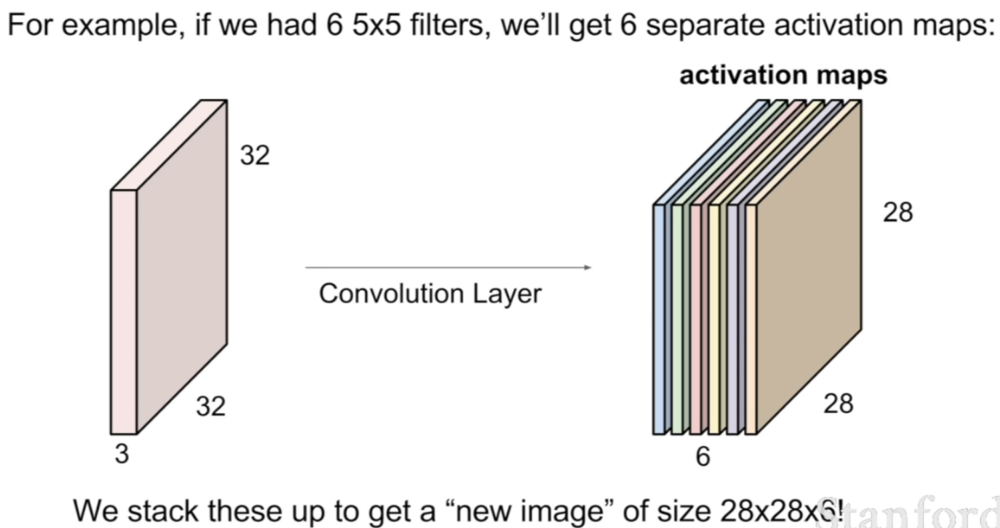 reference:Youtube-StanfordUniversity
reference:Youtube-StanfordUniversity
6개의 activation maps는 filter를 통해 파악하고자 하는 1차적인 이미지의 패턴이 형상화 되어있을 것이다. 예를 들어 위 그림에서는 각 activation map에 가로 성분 패턴이 있는 곳, 세로 성분 패턴이 있는 곳, 원형 성분 패턴이 있는 곳, 타원 성분 패턴이 있는 곳, 평면 성분 패턴이 있는 곳, 점 성분 패턴이 있는 곳이 활성화 되어 있을 것이다. 따라서 이미지가 Convolution layer를 한번 거치고 나면 ‘패턴이 파악된’ 이미지 형태의 output이 생기게 되는 것이다. 또한 각 activation map은 이미지의 같은 곳을 보더라도 다른 패턴을 파악해내는 뉴런에 빗댈 수 있다. 아래 그림처럼 ‘패턴이 파악된’ 이미지를 다시 convolution layer에 통과시키는 경우를 보자.
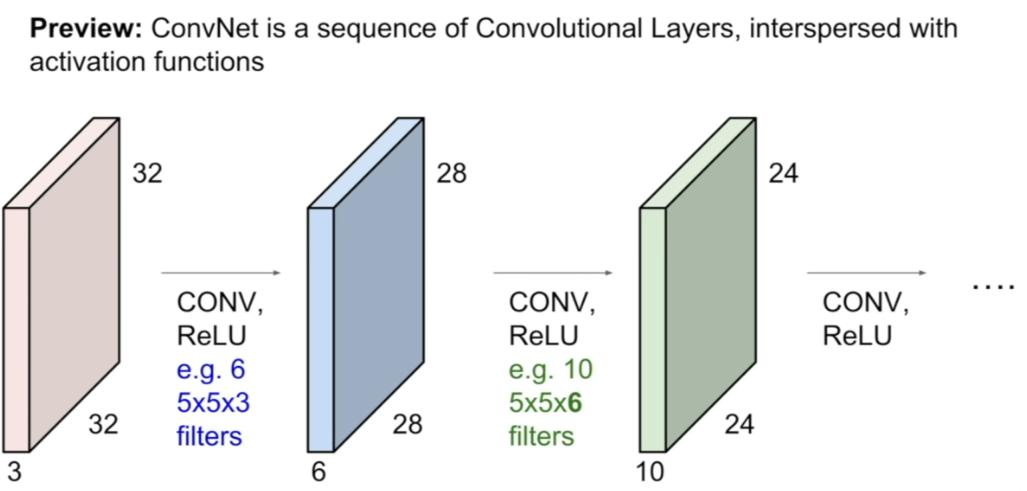 reference:Youtube-StanfordUniversity
reference:Youtube-StanfordUniversity
초록색 activation map (24x24x10)은 5x5x6 사이즈의 kernel matrix 10개로 convolution 시켜서 얻은 결과이다. 초록색 activation map은 이제 파악된 패턴 끼리 연관성을 갖는 고차원적인 output이 된다. 예를 들자면 한 kernel matrix를 통과한 activation map에는 가로 성분은 없고 세로 성분만 있으며 선 끝에 원형이 있는, 즉 이미지 내에서 사탕모양의 패턴이 있는 곳이 활성화 된 결과물일 것이다. 이런 식으로 convolution layer를 통과할 때 마다 고차원의 패턴을 파악하게 된다.
학습을 거듭할 수록, kernel matrix는 loss function을 줄이는 방향으로 업데이트 될 것이고 (즉 Multilayer Perceptron의 weight 값이 kernel matrix의 성분에 해당한다.) 이는 곧 CNN이 이미지를 잘 파악할 수 있는 핵심적인 패턴을 학습한다는 뜻이다.
Pooling
Convolution layer을 많이 사용할수록 학습해야 할 변수가 많아지기 때문에, Pooling이란 기법을 통해 얻은 데이터의 차원 축소한다. 보통 max pooling을 많이 사용하며 그 방식은 아래의 그림과 같이 확인할 수 있다.

Pooling layer 역시 사용자가 정의하며, max pooling의 경우 kernel matrix에 의해 convolution 곱이 된 결과 중 가장 큰 값만 사용하는 방식이다.
Fully Connected Layer
여태까지의 과정은 Convolution layer를 여러 번 통과시키고 pooling을 통해 축소된 형태의 고차원 패턴이 파악된 이미지를 생성시키는 것이다. 이제 고차원 패턴이 파악된 이미지를 1차원적으로 flatten 시켜서 이를 여러 노드로 구성된 fully connected layer에 통과시킨다.
fully connected 되어 있기 때문에 모든 노드들은 각각 고차원 패턴이 파악된 이미지의 모든 정보를 받아들이게 되며 이 노드들은 우리가 사물을 볼 때 사물의 핵심 특징을 인지하는 뉴런으로 보면 된다. 최종 단계의 각 노드(perceptron)들은 예를 들자면 ‘포유류 동물의 귀’, ‘기계 부품’, ‘사람 표정’ … 등 을 볼 때 활성화 되는 뉴런으로 대응할 수 있다. 만약 ‘포유류 동물의 귀’, ‘긴 주둥이’, ‘젤리 발바닥’, ‘부슬부슬한 털’, ‘산책에 쓰이는 목 줄’ 등에 해당하는 뉴런이 활성화 되면 최종적으로 ‘강아지’라고 인식하게 되는 것이다!
손글씨를 파악하는 Convolutional Neural Netowork의 architecture은 아래 그림과 같이 나타낼 수 있다.
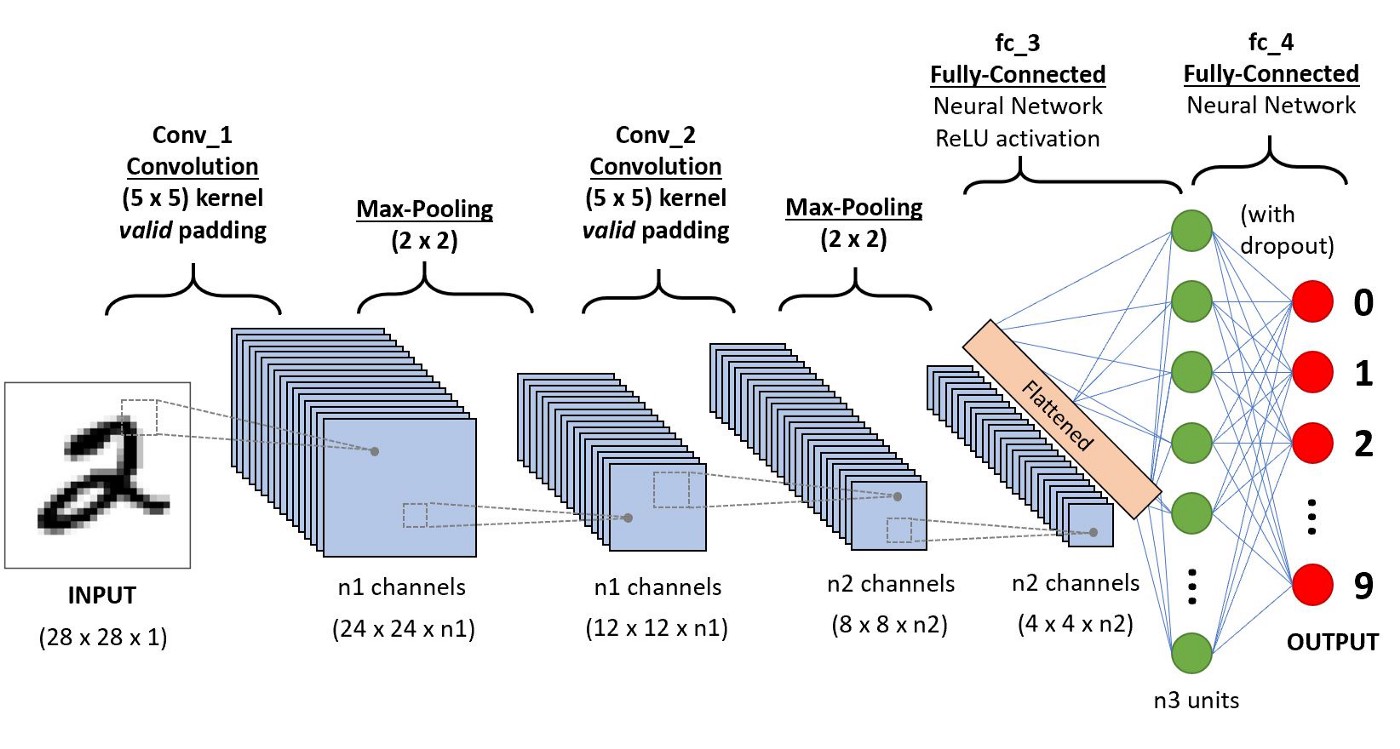
Example
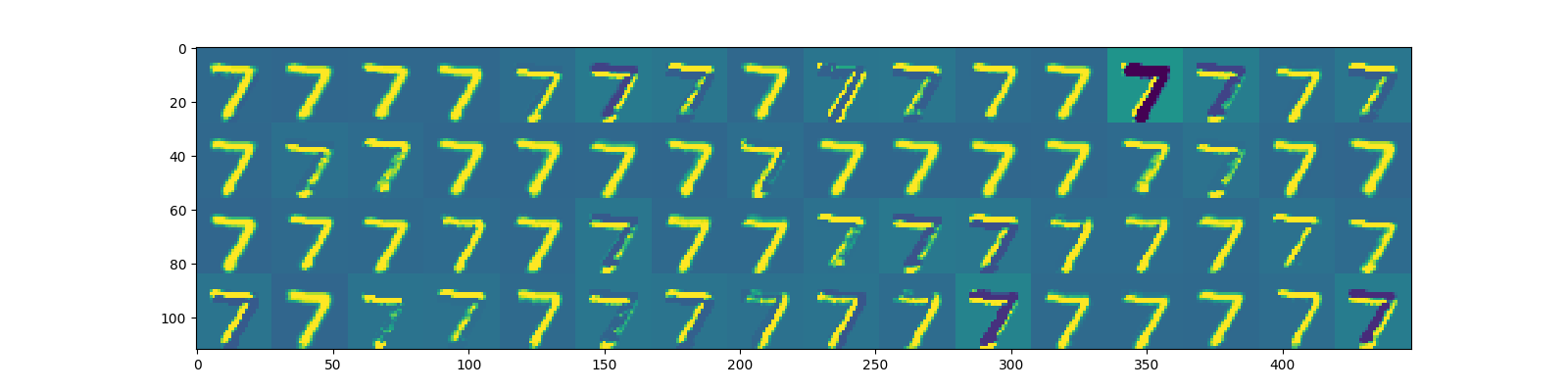
다음은 손글씨 숫자를 인식하는 모델을 딥러닝을 통해 학습시킨 결과이다. 학습이 완료되었을 때 숫자 7에 대해서 맨 처음 16개의 kernel matrix를 가지는 convolution layer를 통과시켰을 때 activation map은 다음과 같다.

1개의 convolution layer를 통과해서 얻어진 1차적인 패턴만 봐도 겹치는 패턴이 많다. activation map들 중 ‘숫자 7처럼 꺾어진 패턴’ 모양으로 활성화 된 것만 절반 이상이 보인다. 그 만큼 패턴이 단순하다는 뜻이다. 주목할 것으로 activation map 중 왼쪽에서 7번 째의 경우 7의 가로 성분을 파악하는 kernel matrix가 학습되었으며 왼쪽에서 9, 10번 째의 경우 7의 대각 성분을 파악하는 kernel matrix가 학습되었음을 볼 수 있다.
3개의 convolution layer을 통과시키고 나서 pooling 시킨 결과는 다음과 같았다.

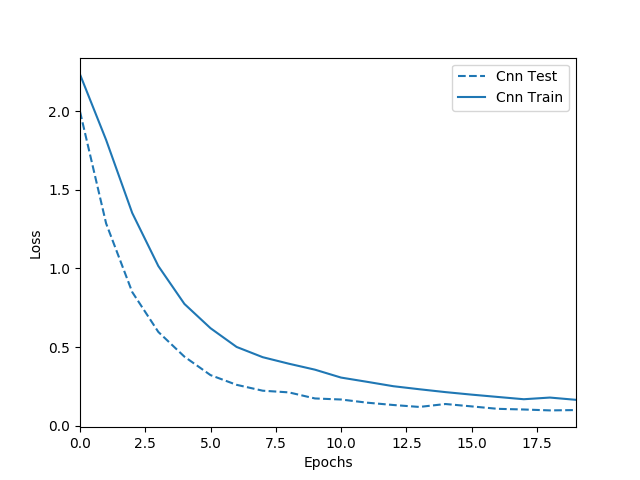
고차원 패턴이라 어떤 패턴이 어떤 모양을 뜻하는 것이다라고 단정 짓기는 힘들지만 왼쪽에서 10번 째 activation map을 볼 때 확실히 고차원 패턴에서도 대각성분이 학습된 것을 볼 수 있다. 아래는 train 및 test data에 대한 loss function 값이다.
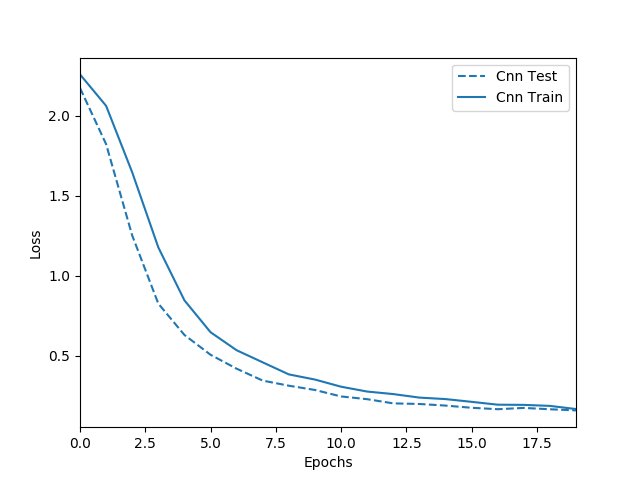
흑백 손글씨와 같이 단순한 패턴을 가지는 데이터의 경우 첫 번째 convolution layer을 통과했을 때만 해도 비슷해보이는 패턴이 많았다. 따라서 더 많은 패턴을 잡아내고자 kernel matrix를 늘려도 더 나은 결과를 기대하긴 힘들 것이다. 아래는 kernel matrix를 64개로 했을 때 1. 첫 번째 convolution layer의 activation map, 2. 세 번째 convolution layer의 pooling 결과, 3. train 및 test data의 loss function을 나타낸 것이다.
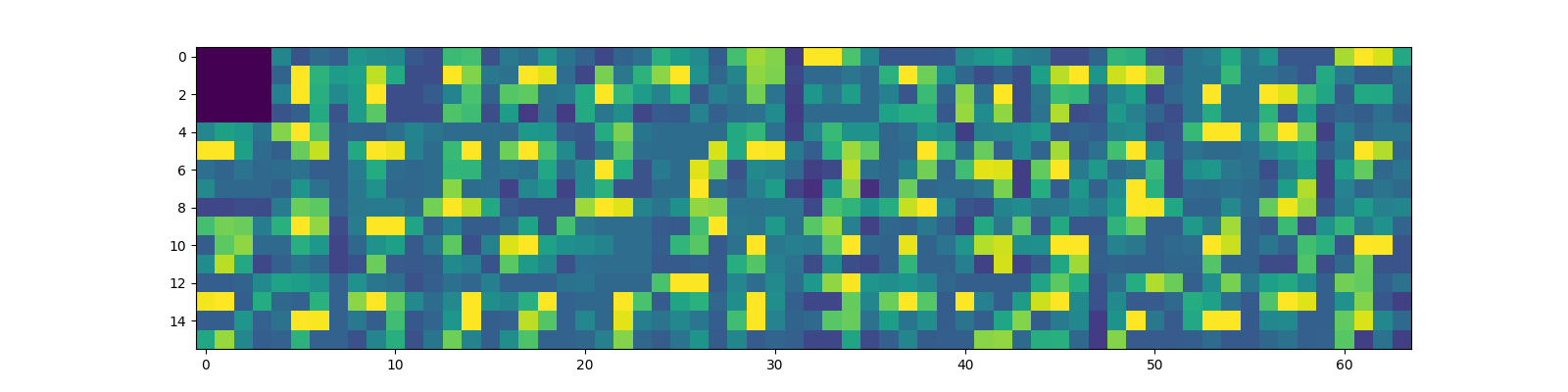
activation function이 아예 0으로 패턴을 잡아내지 못한 kernel matrix도 보인다. 그리고 kernel matrix가 16개일 때에 비해 결과가 크게 개선되지 않음을 확인할 수 있다.
Reference
위 강의에 정말 설명이 잘 되어있으니 좀 더 자세한 내용을 알고 싶다면 참고하면 좋다.


Leave a comment